本プレスリリースURL
https://prtimes.jp/main/html/rd/p/000000021.000040625.html
プログラミング不要、日本語による指示で画像認識・制御コードもすべてAIが自動生成
株式会社チトセロボティクス(本社:東京都文京区、代表取締役社長:西田亮介、以下「当社」)は、大規模言語モデル(LLM)および視覚言語モデル(VLM)を活用した「産業用ロボットの自然言語動作指示システム」の研究開発を開始いたしました。
本研究は、工場現場などにおけるロボット教示の専門知識を必要としない操作環境の実現を目的とし、日本語による指示と画像入力のみでロボットの動作が可能となる新たなシステム構築を目指します。
■背景:産業用ロボットの普及とその限界
近年、産業用ロボットの活用は製造業を中心に急速に進みましたが、一方で熟練オペレータの不足や、自動化への柔軟な対応が難しいという課題が浮き彫りになっています。特に、従来の「教示再生方式」では、環境の変化や多品種少量生産への対応が困難であることが課題となっています。
このような課題に対し、対象物や環境の変化に応じてリアルタイムに補正を行うセンサフィードバック制御が注目されています。中でも、画像を用いた「ビジュアルフィードバック制御」は有望なアプローチの一つです。しかしながら、これらの手法では、画像処理プログラムやロボット運動制御アルゴリズムを専門技術者が個別に開発・実装する必要があり、システム立ち上げには多くの時間とコストがかかるという問題がありました。
こうした背景の中で、近年急速に進化している生成AI(大規模言語モデルや視覚言語モデル)に注目が集まっています。自然言語や画像をもとに、コードや手順を自動生成できる生成AIの技術を応用すれば、従来の立ち上げ工数の大幅な削減が期待されます。
とはいえ、生成AIを実環境の産業用ロボットと統合し、高速かつ高精度な動作を実現するためには、システムインテグレーション上の課題も少なくありません。特に、高速で精密な制御が求められる産業用ロボットにおいて、生成AIとどのように連携させるかは、これまで解決の難しい技術的課題とされてきました。
本研究では、これらの課題に取り組み、生成AIと産業用ロボットを結びつける新しい仕組みの構築を目指しています。

■研究の概要:LLM/VLMによる直感的なロボット制御
本研究で開発を進めているのは、大規模言語モデル(LLM)および視覚言語モデル(VLM)を用いて、非エンジニアでも自然言語と画像入力のみでロボットに動作指示を行える産業用ロボット制御システムです。
従来の産業用ロボットにおいては、「教示再生方式」によってロボットに動作を覚えさせる必要があり、専用ソフトやハードウェア、また専門的なスキルが求められてきました。
本提案ではこの教示プロセスを根本的に見直し、一般作業者による自然言語と視覚的な入力のみで、直感的に産業用ロボットを制御できる新たなアプローチを提示します。
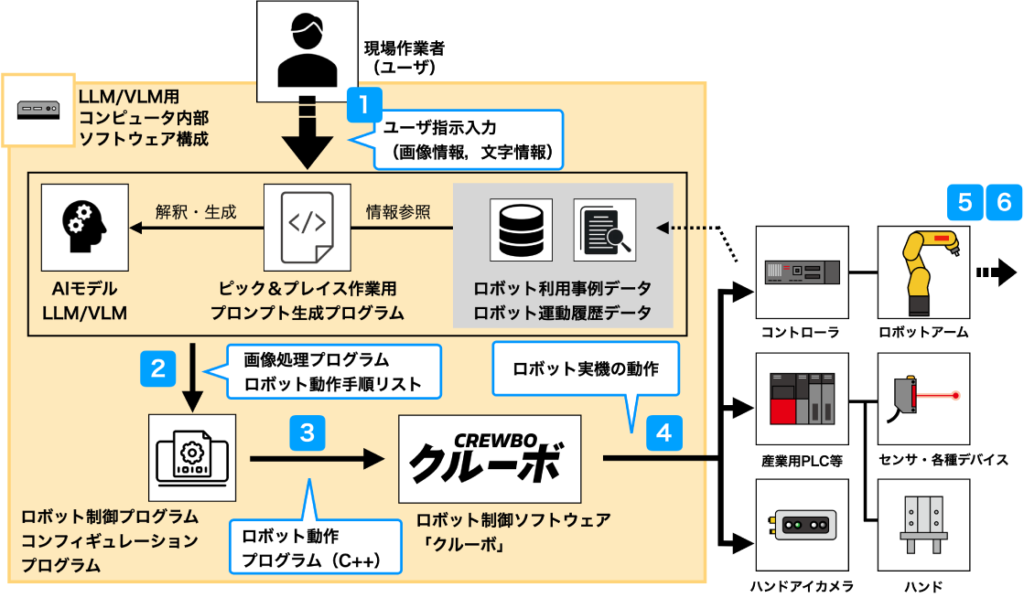
システムの構成要素
(1)ユーザーからの自然言語と画像入力
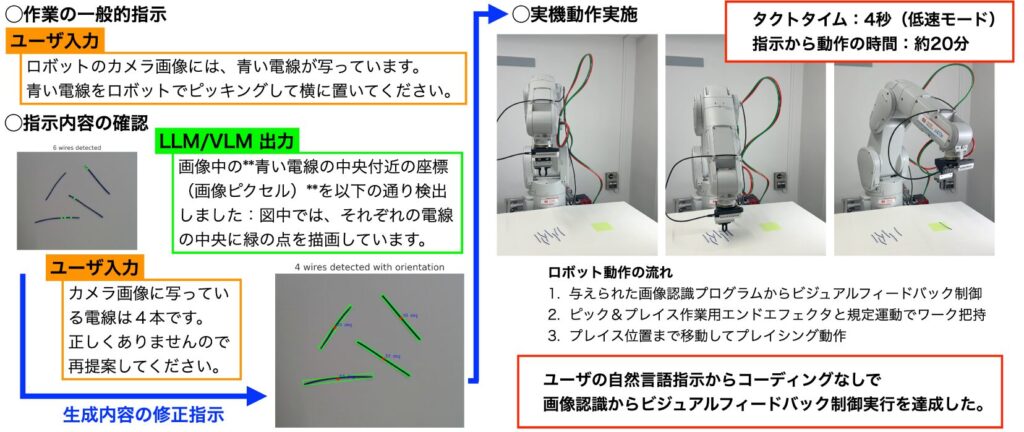
ユーザーは、たとえば「青い電線をピッキングして横に置いてください」といった日本語による作業指示を与えます。
加えて、対象物を写した画像(あるいはカメラからのリアルタイム映像)をアップロードすることで、視覚的な情報もロボットに提示されます。
(2)LLM/VLMによるタスクの解釈
受け取った自然言語と画像情報をもとに、LLM(大規模言語モデル)とVLM(視覚言語モデル)が作業指示の意味を解釈します。
この段階で、必要な処理として以下が自動で生成されます。
- 対象物を検出するための画像認識プログラム(OpenCVベースのC++コード)
- ロボットの基本動作命令列(移動、把持、リリースなど)
- 動作手順をまとめたシーケンス
- それらを統合したC++実行プログラムおよびパラメータファイル
(3)ロボット制御用のプログラム生成と実行準備
生成されたコードは、当社のロボット制御ソフトウェア「クルーボ」と連携し、実機ロボットに直接適用されます。
クルーボは、事前のキャリブレーションやワールド座標系の定義を必要とせず、画像内のピクセル座標情報のみで動作を行うため、環境変動にも柔軟に対応可能です。
(4)実行時のビジュアルフィードバック制御
動作実行時には、ロボットに搭載されたハンドアイカメラやレーザセンサの映像フィードバックを利用し、リアルタイムで位置補正・把持修正を行います。
これにより、0.02mm以下の位置精度での把持・配置動作が実現され、従来の静的ティーチング方式よりもはるかに柔軟かつ高精度な作業が可能になります。

システムの全体像と流れ
- ユーザー指示入力(自然言語・画像)
↓ - LLM/VLMによるタスク理解とプログラム生成
・画像認識プログラム(detectTarget)
・ロボット動作シーケンス(基本コマンド:moveToJointAngles(), grasp() など)
・C++ベースの実行プログラム・パラメータファイル
↓ - コンフィギュレーションプログラムが統合・出力
↓ - クルーボを介してロボットへ動作指示
↓ - リアルタイムでセンサ情報に基づくビジュアルフィードバック制御
↓ - 高精度・高信頼な作業実行
基本原則と工夫点
- プロンプト構造の自動埋め込みにより、トークン数を最適化し、LLM/VLMの制限を回避
- ループ処理を含むロボット動作の基本構造を明示し、収束動作や追従動作にも対応
- 他のロボットとの情報共有を見据えた共通プロンプト設計
- ノンキャリブレーション型制御の実装により、現場ごとの手間とコストを削減
■特徴と成果
コーディング不要: ユーザは「青い電線をピッキングして横に置いてください」といった自然言語で指示
高精度: 0.02mm以下の精度をビジュアルフィードバック制御で実現
高速性: 低速モードでのタクトタイム約4秒、指示から動作まで約20分で完了
拡張性: 複数エンドエフェクタ・複数台協調・組付け作業など多様な応用が想定可能